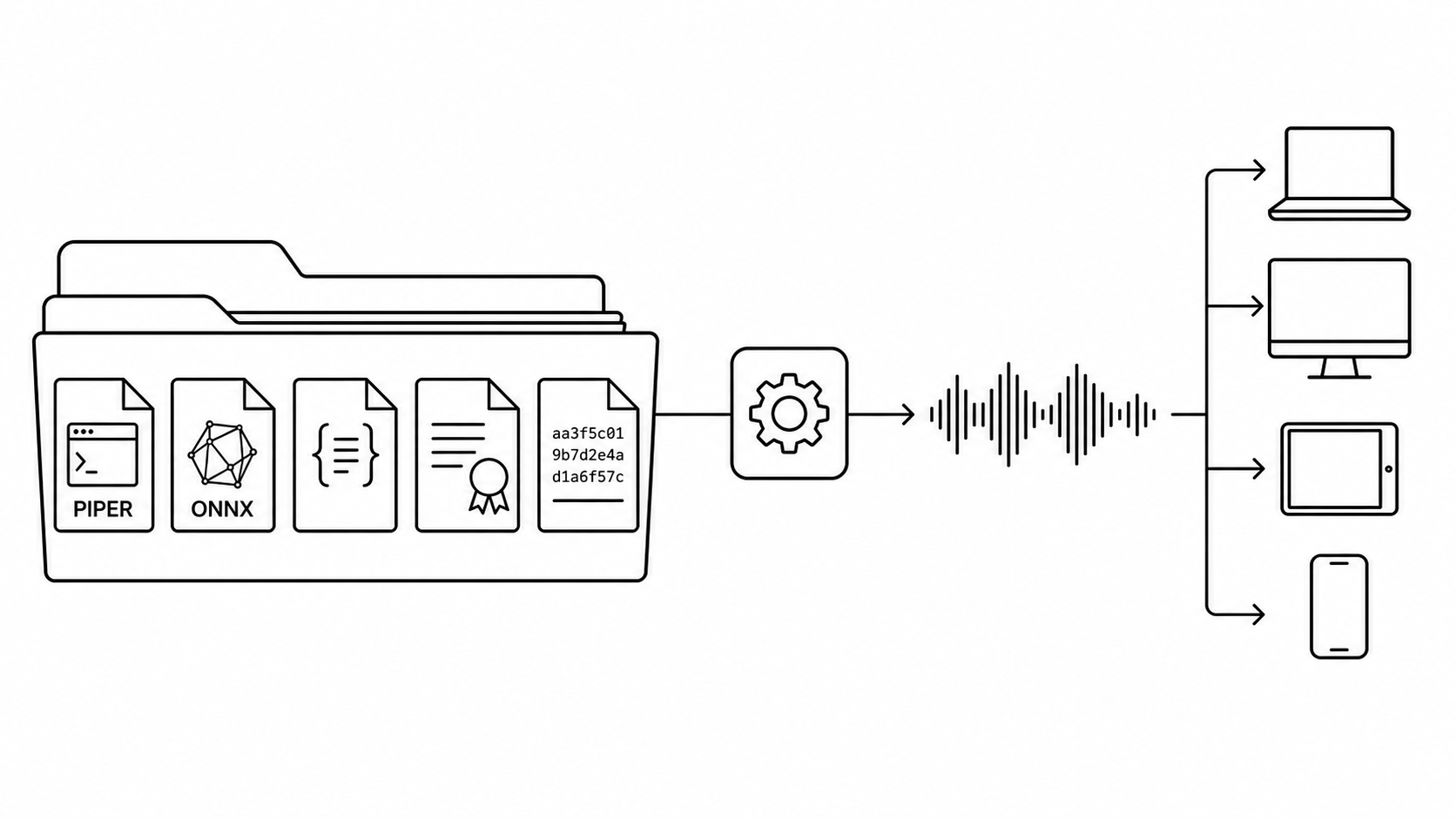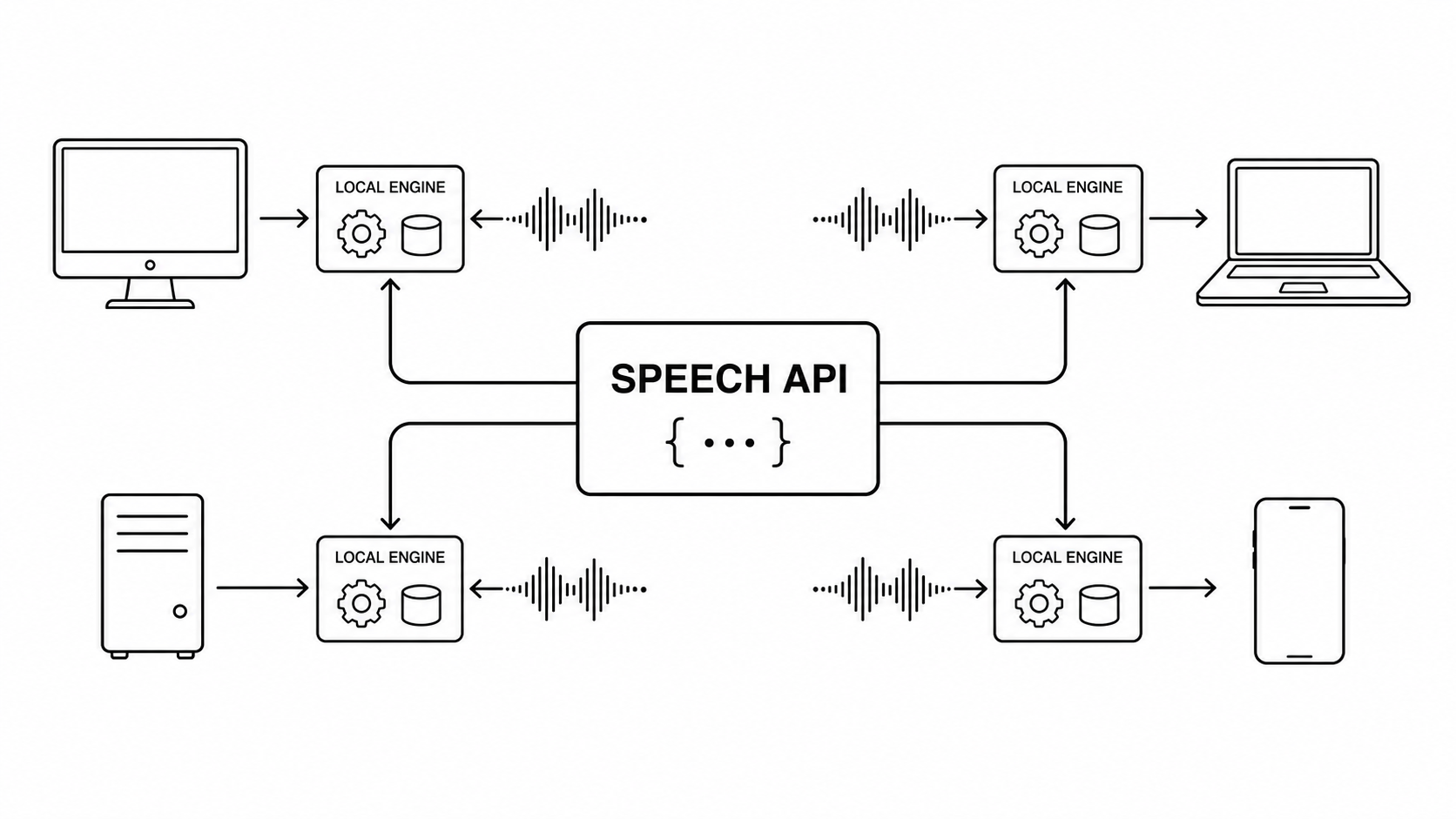
The fastest way to ruin a local speech feature is to let the UI know too much.
A “Play” button should not know where an ONNX model lives. It should not know Piper flags. It should not know whether Linux uses one audio path and macOS another. It should not care whether the voice came from Piper today or sherpa-onnx tomorrow.
Teams skip this boundary because the demo is close and the deadline is rude. They wire the UI straight into a TTS library.
Six weeks later, reality arrives: a second engine for Linux, a tiny fallback for older laptops, a different voice setup for iOS, and a cancel button that actually stops the audio. Suddenly half the app is tangled in routing logic.
The cure is a product-level Speech API.

Write the Contract First
A good local speech service has a tiny, simple public API:
type SpeakRequest = {
text: string;
voiceId?: string;
priority?: "interactive" | "background";
interrupt?: boolean;
metadata?: Record<string, string>;
};
type SpeakJob = {
id: string;
state: "queued" | "synthesizing" | "playing" | "done" | "cancelled" | "failed";
};
interface SpeechService {
speak(request: SpeakRequest): Promise<SpeakJob>;
cancel(jobId: string): Promise<void>;
cancelAll(): Promise<void>;
listVoices(): Promise<VoiceInfo[]>;
preflight(): Promise<PreflightReport>;
}
Notice what is missing from this interface:
- No hardcoded ONNX file paths.
- No CLI flags.
- No platform-specific audio device IDs.
- No direct
importstatements for Piper or sherpa-onnx. - No assumption that synthesis and playback happen at exactly the same time.
That missing stuff is the design.
Your UI does not need to know how speech gets made. It needs to know whether a job was requested, started, stopped, or failed.
Keep the Mess Behind the Boundary
Inside the service, you want to split up the jobs cleanly:
SpeechService
VoiceCatalog
TextNormalizer
SentenceSplitter
Queue
EngineRouter
EngineAdapter
AudioCache
Player
Telemetry
Each piece gets one job.
The VoiceCatalog knows what voices you have installed. The TextNormalizer cleans up messy text. The SentenceSplitter chops it into safe chunks. The Queue figures out what plays first. The EngineRouter picks the right backend. The EngineAdapter actually talks to Piper, sherpa-onnx, or eSpeak NG. And the Player talks to the OS audio system.
The single most important boundary here is the adapter:
interface TtsEngineAdapter {
id: string;
synthesize(input: EngineSynthesisInput): Promise<EngineSynthesisOutput>;
preflight(): Promise<EngineHealth>;
}
Once every engine implements this interface, swapping backends stops being a rewrite and becomes ordinary product work.
Queue Sentences, Not Novels

Unless you’re explicitly rendering an audiobook in the background, never send a giant document to your synthesis engine all at once.
For interactive UI speech, break the text down into small, sentence-sized jobs:
The deployment finished successfully.
Three containers restarted.
One warning remains in the database migration log.
This gives you four wins:
- Faster time-to-first-audio: The user hears the first sentence while the second one is still generating in the background.
- Fast cancellation: If the user hits pause, you just drop the queued chunks instead of trying to violently kill a locked-up subprocess.
- Easy retries: If one chunk fails, you can retry it without having to restart the entire document.
- Better caching: You are much more likely to hit the cache for short, common phrases.
Your queue also needs to understand priorities. A critical screen-reader alert should interrupt a long background read, but a background read should not interrupt a critical warning. For speech, user intent matters more than strict First-In-First-Out (FIFO) queueing.
Start with a basic policy:
if request.interrupt:
cancel queued jobs
stop current playback
start this request
else:
append request to queue
Add priority tiers later. Keep the first policy simple enough to debug when it breaks.
Route by Capability, Not Guesswork
Your router shouldn’t pick engines based on hardcoded IF statements. Give it some constraints.
Define exactly what each engine is allowed to do:
type EngineCapability = {
languages: string[];
platforms: string[];
supportsStreaming: boolean;
supportsSpeedControl: boolean;
maxRecommendedChars: number;
licenseClass: "permissive" | "copyleft" | "commercial" | "unknown";
};
Then, make your routing decisions completely explicit:
Need en-US, interactive, desktop:
try Piper voice en-us-lessac-medium
fallback to eSpeak NG en-us
Need embedded ARM, native library preferred:
try sherpa-onnx compatible model
fallback to eSpeak NG
Need diagnostic mode:
use eSpeak NG
This is where toolkits like sherpa-onnx shine. Its platform support matters when a CLI wrapper is no longer enough. Piper can still be your best desktop option, and eSpeak NG can remain the emergency voice. A good architecture leaves room for all three.
Package the Speech Stack in Layers

To keep things flexible, separate your deployment into three distinct pieces:
- The App Package: Your UI, business logic, and the Speech API layer.
- The Engine Package: The actual binaries (Piper, sherpa-onnx, eSpeak NG) and their platform-specific native libraries.
- The Voice Package: The ONNX models, JSON configs, dictionaries, and licenses.
By separating these out, you can answer “yes” to these very practical questions:
- Can we fix a mispronounced word in a dictionary without doing a full app update?
- Can we keep our initial installer small and download heavy voices on-demand?
- Can users delete voices they don’t use to save space?
- Can we rollback a buggy voice model easily?
- Can we push a new Linux binary without touching the Windows release?
Unless an app store forces your hand, do not make the main installer the only way to update the speech stack.
Preflight Before the User Clicks Play
A solid local TTS system should test itself before the user ever clicks “Play.”
Your preflight() method should check:
- Is the engine binary actually on disk?
- Does it have execution permissions?
- Did the native libraries load?
- Is the ONNX model file there?
- Is the config JSON there?
- Do the file checksums match what we expect?
- Can we write to the audio cache folder?
- Can we access the OS audio device?
- Can we synthesize one tiny test sentence successfully?
Return the results as simple, structured JSON:
{
"ok": false,
"checks": [
{
"name": "voice-model-checksum",
"ok": false,
"message": "Expected sha256 abc..., got def..."
}
]
}
A good preflight turns “TTS doesn’t work” into “the voice model is corrupted.” That is the difference between panic and repair.
Keep Playback Separate
Audio playback involves a lot of messy, platform-specific code. Keep it hidden behind an interface:
interface AudioPlayer {
play(file: string): Promise<void>;
stop(): Promise<void>;
setVolume(value: number): Promise<void>;
}
On desktop, you might wire this up to native playback APIs or a bundled media player. On mobile, you’ll talk to native audio sessions. On a headless server, you might just skip playback entirely and pipe the WAV bytes directly to another service.
The rule is simple: synthesis makes audio; playback consumes it. Mix them too early and caching, testing, and cancellation get worse.
Speech Must Fail Without Taking the App Down
When TTS breaks, your app should not panic.
Categorize your errors clearly:
VOICE_NOT_FOUND
ENGINE_MISSING
MODEL_CORRUPT
SYNTHESIS_TIMEOUT
AUDIO_DEVICE_UNAVAILABLE
TEXT_UNSUPPORTED
LICENSE_BLOCKED
Then, figure out how to handle them smoothly:
AUDIO_DEVICE_UNAVAILABLE: Show a little UI toast telling the user to check their system settings.MODEL_CORRUPT: Silently start a background download to fix the voice.SYNTHESIS_TIMEOUT: Immediately fall back to eSpeak NG.TEXT_UNSUPPORTED: Log a telemetry event for your QA team, but just skip reading that specific sentence so the app doesn’t crash.
Speech is an enhancement. It should never take the core app hostage.
Design for Change
Piper vs. sherpa-onnx is the wrong argument. The durable problem is change.
Engines will deprecate. Models will get better. Licenses will change. Audio devices will get unplugged randomly. If you hardcode your engine calls today, you’ll be paying off that tech debt in six months.
A clean Speech API gives the product a stable surface while the speech stack keeps changing underneath it.
That is the architecture you want: boring at the top, flexible at the bottom, honest about failure everywhere.