The hard part of local speech is not making a laptop talk.
The hard part is making speech survive contact with real product behavior: messy documents, long jobs, interrupted laptops, missing models, privacy expectations, exports, retries, and users who do not care which engine failed.
Dream TTS is where that became obvious.
The short version:
Dream TTS is a local speech studio that turns text, documents, and web articles into narrated audio, keeping all of the processing strictly on the user’s machine.
That sentence sounds simple only if you ignore the word “local.”

The Real Bet Was Durability
The demo question is easy: can we make a laptop talk? Dream TTS had a harder bet:
- Can a normal user drop in a messy, chaotic PDF without crashing the app?
- Can the app clean that text into something the engine can actually read?
- Can a two-hour audiobook generation job survive the user closing their laptop halfway through?
- Can we make this work smoothly on both desktop and mobile?
- Can the audio output be saved to a real library instead of just dumping a WAV file in a temp folder?
- Can we keep absolute privacy as a default feature, not just a marketing promise?
Those questions chose the architecture for us.
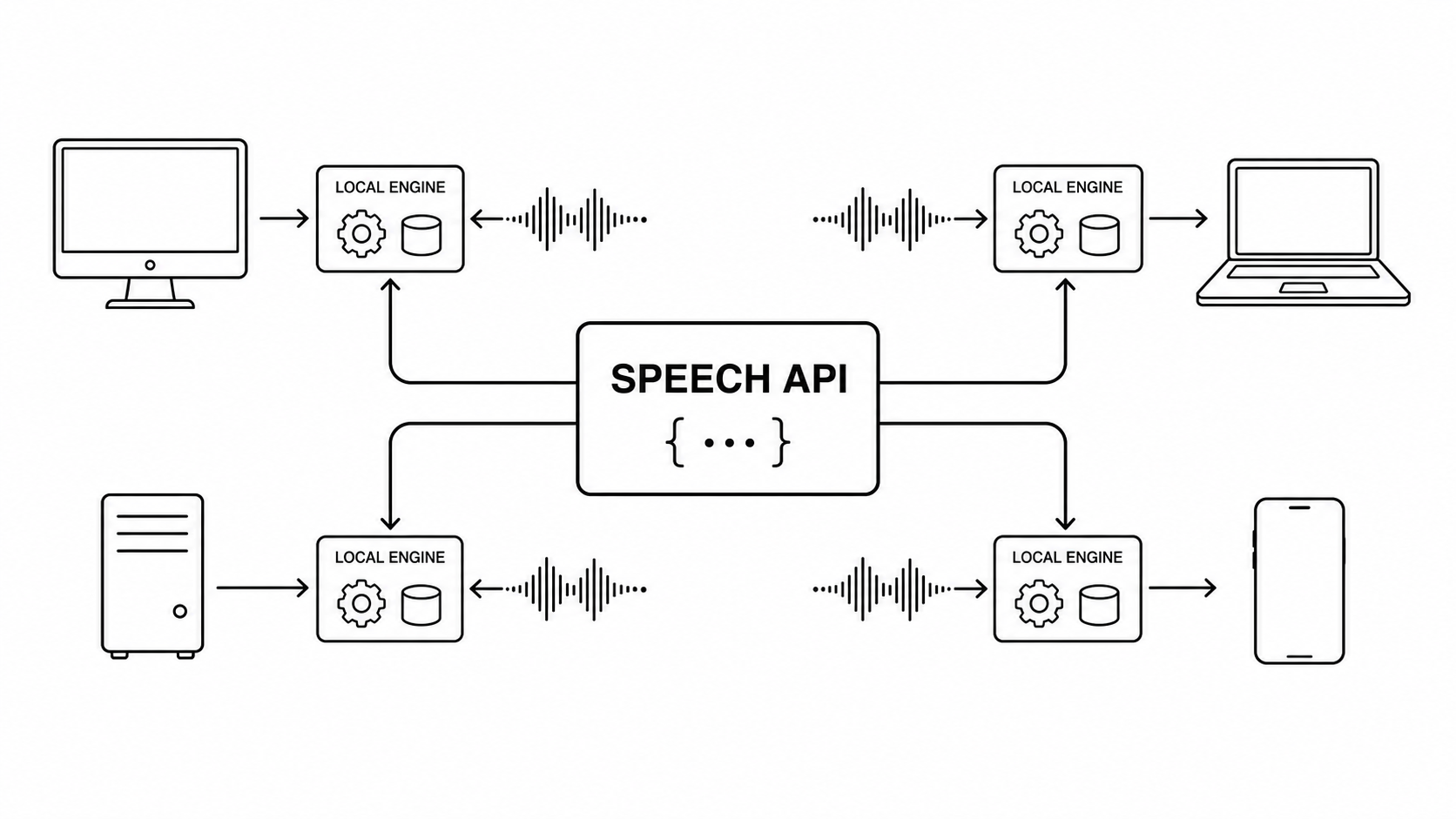
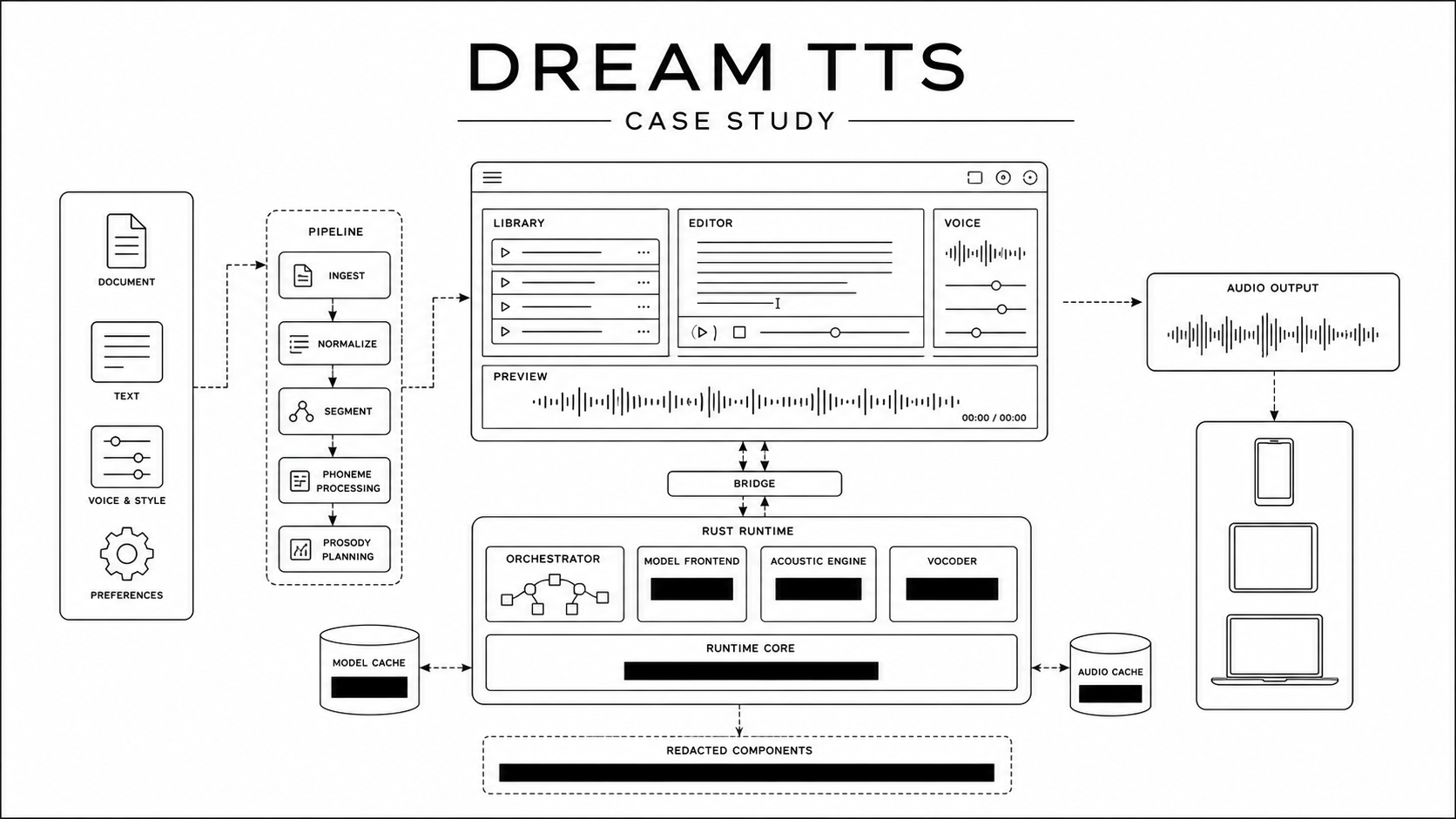
Flutter owns the product surface: screens, controls, imports, playback, the library, and the small state changes that make the app feel alive.
Rust owns the durable work: reading files, cleaning text, chunking sentences, firing the TTS engine, saving state, managing cache, and exporting final audio.
The bridge connecting Flutter and Rust is intentionally boring. There’s no massive shared memory state or crazy object graphs. It’s just simple IDs, small requests, JSON responses, and basic lifecycle hooks.
That simplicity keeps the app from collapsing.
Keep the Speech Factory Out of the UI
Prototype code loves the UI layer. Product code pays for that laziness.
Once users can import 50-page documents, swap voices, pause generation, restart the computer, and resume the job, the little “TTS button” has become a production factory.
If your UI tries to run that factory, every weird platform quirk is going to leak into your frontend code.
Dream TTS drew a hard line:
The UI owns the user experience.
The Runtime owns the speech work.
That rule saved us from so many arguments. If a feature affects synthesis accuracy, job recovery, or saving an audio file, it goes below the bridge into Rust. If a feature affects how a user clicks through the app, it stays above the bridge in Flutter.
Simple lines are useful because teams can remember them.
Designing for Risk

The biggest risks were not exotic AI problems. They were ordinary software problems wearing a speech costume.
Documents are a mess. A PDF is not text; it’s a visual layout. When you extract text from it, you get running headers, page numbers, weird line breaks, and pure garbage characters. Web pages are just as bad, filled with cookie banners and nav menus. Dream TTS treats importing a file as a heavy cleanup job first, and a speech problem second.
Long jobs fail in new ways. If a single paragraph fails to generate, you just retry it. If a three-hour audiobook generation fails, you need to save state. That means you need chunk manifests, progress tracking, pause/resume buttons, cache checks, and a way to glue the final audio together without loading a 2GB WAV file into RAM.
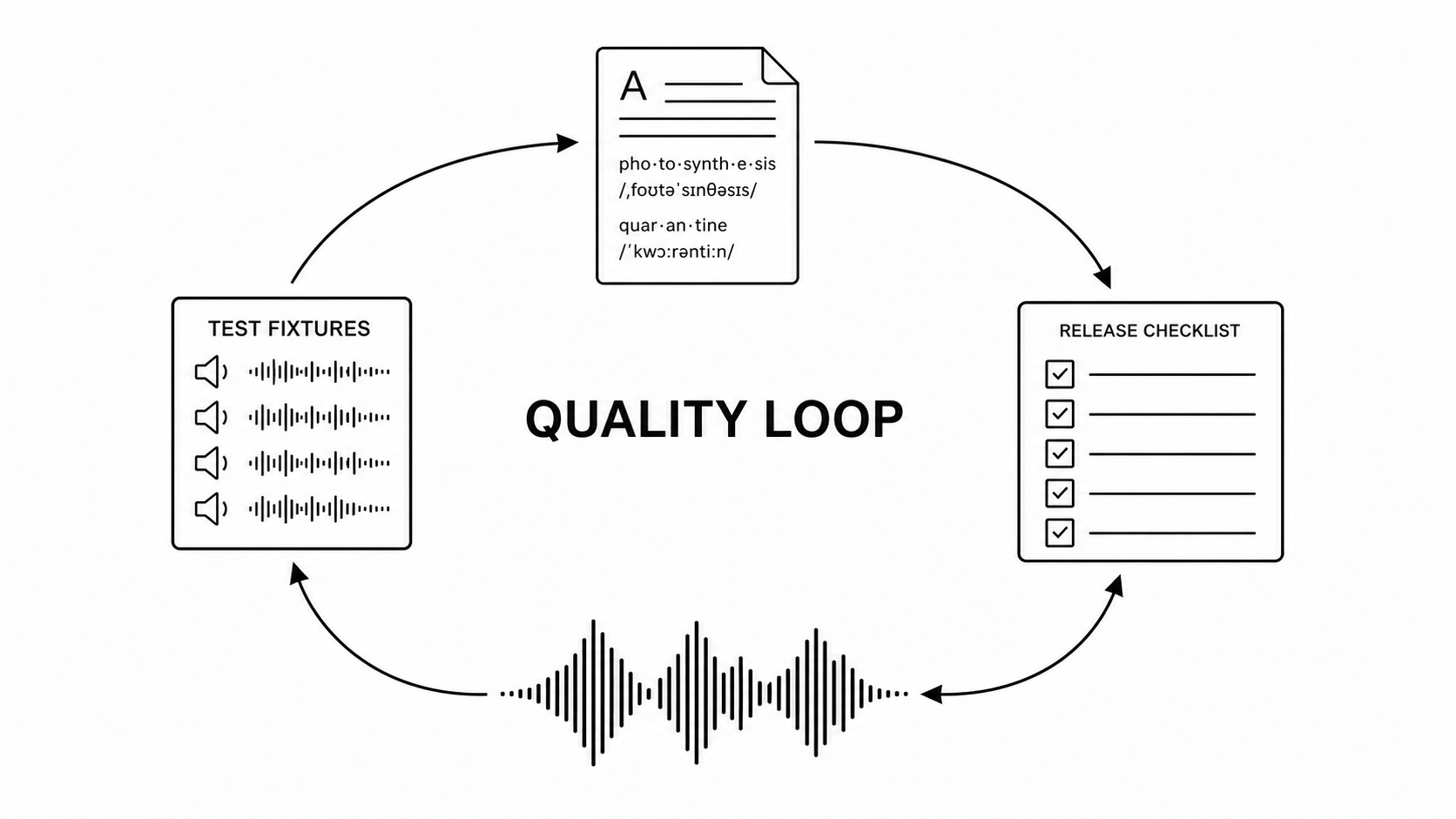
Voice quality is inconsistent. Just because the TTS engine returns a file doesn’t mean the audio is good. Dream TTS checks for quality at the chunk level. It algorithmically rejects silent or broken audio, retries it safely, and makes sure bad audio doesn’t get baked into the middle of a massive final file.
Platforms disagree on everything. Desktop and mobile don’t fail the same way. You have to deal with app sandboxes, specific user data directories, code signing, native audio sessions, and weird hardware backends. You have to handle these platform quirks explicitly, rather than pretending a generic framework handles it all perfectly.
Distribution changes the architecture. Voice models aren’t just files; they are a commitment to your users. Some models are bundled in the app, some are downloaded later, and some might be brought in by the user themselves. Every one of those paths needs its own lifecycle.
None of this is glamorous. It is why the product works.
A Narrow Bridge Prevents a Wide Mess
Keeping the Flutter/Rust bridge small forces discipline.
The UI should only be able to say things like:
configure the runtime
import this source material
start this job
pause this job
resume this job
show me the status
show me the history
give me the transcript
export the final audio
The UI shouldn’t know how a sentence gets chunked, where the cache lives on the hard drive, how the engine handles a timeout, or which specific file path the ONNX model is using today.
This strict separation also made testing way less stressful. We could test the Rust logic without worrying about Flutter widgets. We could redesign the UI without accidentally breaking the synthesis loop. And when something failed, it was easy to ask: is this a UI bug, a bridge bug, or a Rust panic?
Good boundaries turn debugging back into engineering.
The Important Decisions Were Structural
The best decisions were structural, not flashy.
For example, the Rust runtime treats the state of a “chunk” as a core feature, not an afterthought. The local cache isn’t just a temp folder; it’s the system’s memory. It’s what allows a long job to pause, recover from a crash, and finally become a finished file.
We also treated the model lifecycle with respect. A bundled model, a downloaded model, and a user-provided model all behave differently. They each need their own validation checks, storage rules, and error messages.
Finally, quality control happens at generation time. Every audio chunk has to earn its way into the final output. That one rule changes the whole product: bad audio is no longer a catastrophe discovered at the end of a two-hour job. It is a routine error the system can recover from.
The Release Ladder

Dream TTS didn’t become a real product the first time it successfully spoke a sentence. It became a product by climbing a ladder:
- Get one voice to speak locally.
- Build a UI that can import, configure, preview, and export.
- Make long generation jobs resumable.
- Get the builds working reliably across different devices.
- Make sure quality checks actually block a bad release, instead of just being something you apologize for later.
That sequence is really important to remember because it’s so easy to get distracted by voice quality early on. A voice that sounds perfectly human is useless if it crashes when the network drops. A blazing-fast engine is dangerous if it silently spits out empty audio chunks. A slick UI is unfinished if it just crashes when a voice model file goes missing.
Trust isn’t a feature you can build in a sprint. Trust is just the absence of small betrayals over time.
Rules Worth Stealing
If you are building a local TTS app, steal these before writing the first line:
Make speech a service, not a button. Your app will eventually need queueing, cancellation, history, caching, exporting, and fallbacks. Give all that complexity its own dedicated home in your architecture.
Build chunks for recovery. We don’t just split text into chunks to save RAM. Chunks are the basic unit of progress. They are what you retry, what you cache, what you pause, and what you review for quality.
Treat importing as part of TTS. Garbage text in equals garbage audio out. The layer of your app that cleans up PDFs and web pages isn’t just menial data parsing; it’s literally directing the voice.
Don’t hide platform quirks. If a specific audio backend isn’t supported on iOS, fail early and loudly. If a model has to live on the hard drive, design your code around real OS directory paths. Put your code signing steps right into the main build script.
Check quality before you assemble. Don’t wait until you’ve generated a massive 10-hour audiobook to find out there’s a silent gap in chapter two. Check the audio chunks while they are still small and cheap to re-generate.
Never log private text. People use local speech apps because they want their data kept completely private. Respect that trust. Never log the raw text payload.
The Real Asset Was Discipline
The most valuable asset in Dream TTS was the discipline around the model:
- A UI layer that stays fast and responsive.
- A native runtime that handles all the heavy lifting.
- A strict bridge that keeps the messy engine details hidden.
- A smart cache that treats long jobs with respect.
- A quality loop built on the assumption that engines will fail.
- A release process that forces us to deal with messy platform realities.
That is the lesson: do not build around today’s favorite engine. Build the product so it can evolve.
Local TTS is moving fast. Voices will get better. Backends will change. Hardware acceleration will spread. The winning architecture can swap in tomorrow’s model without rewriting the app.
Dream TTS is our answer to that challenge. It’s a reminder that local speech is only truly compelling when the entire app is built on a foundation of trust.