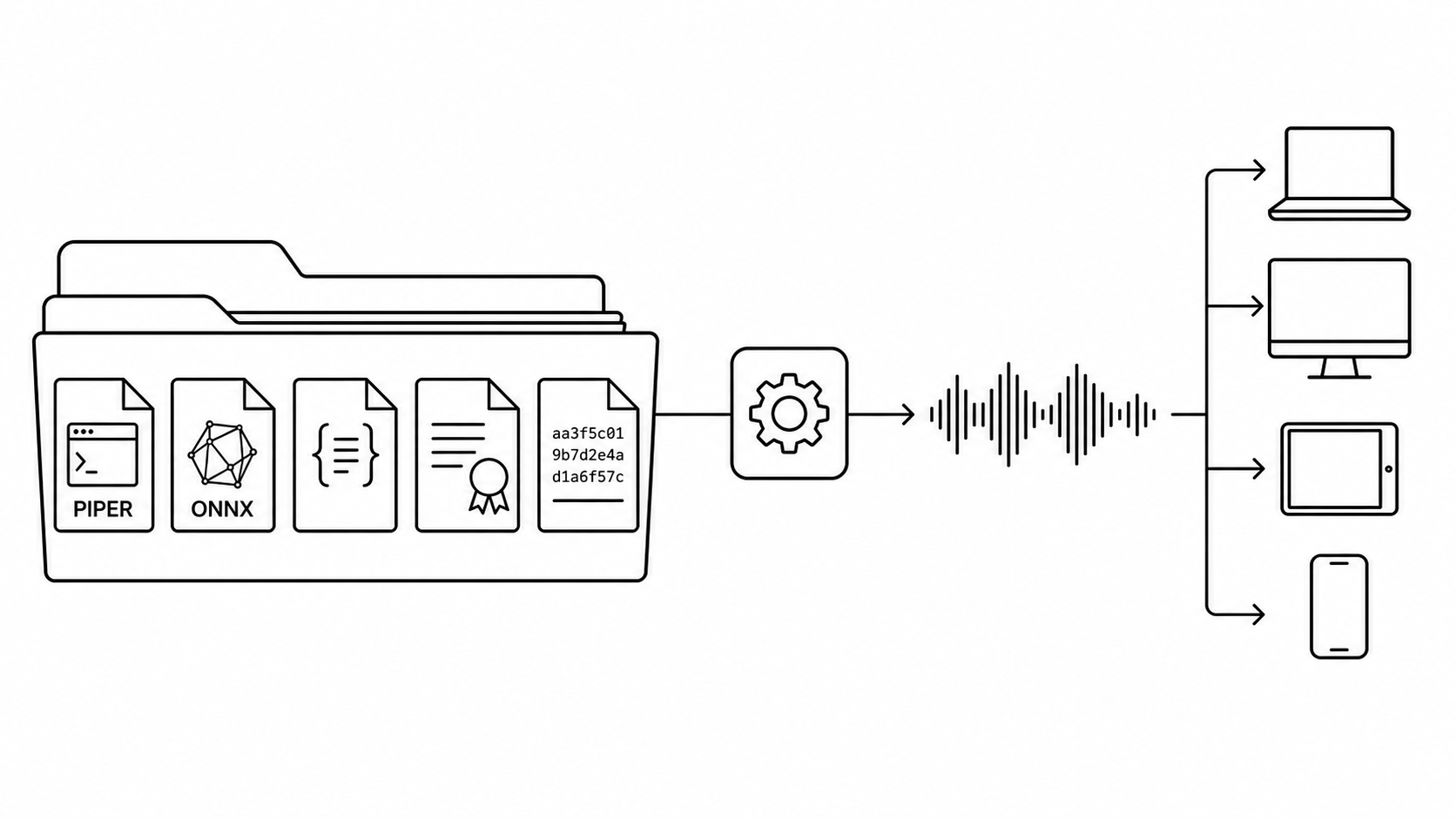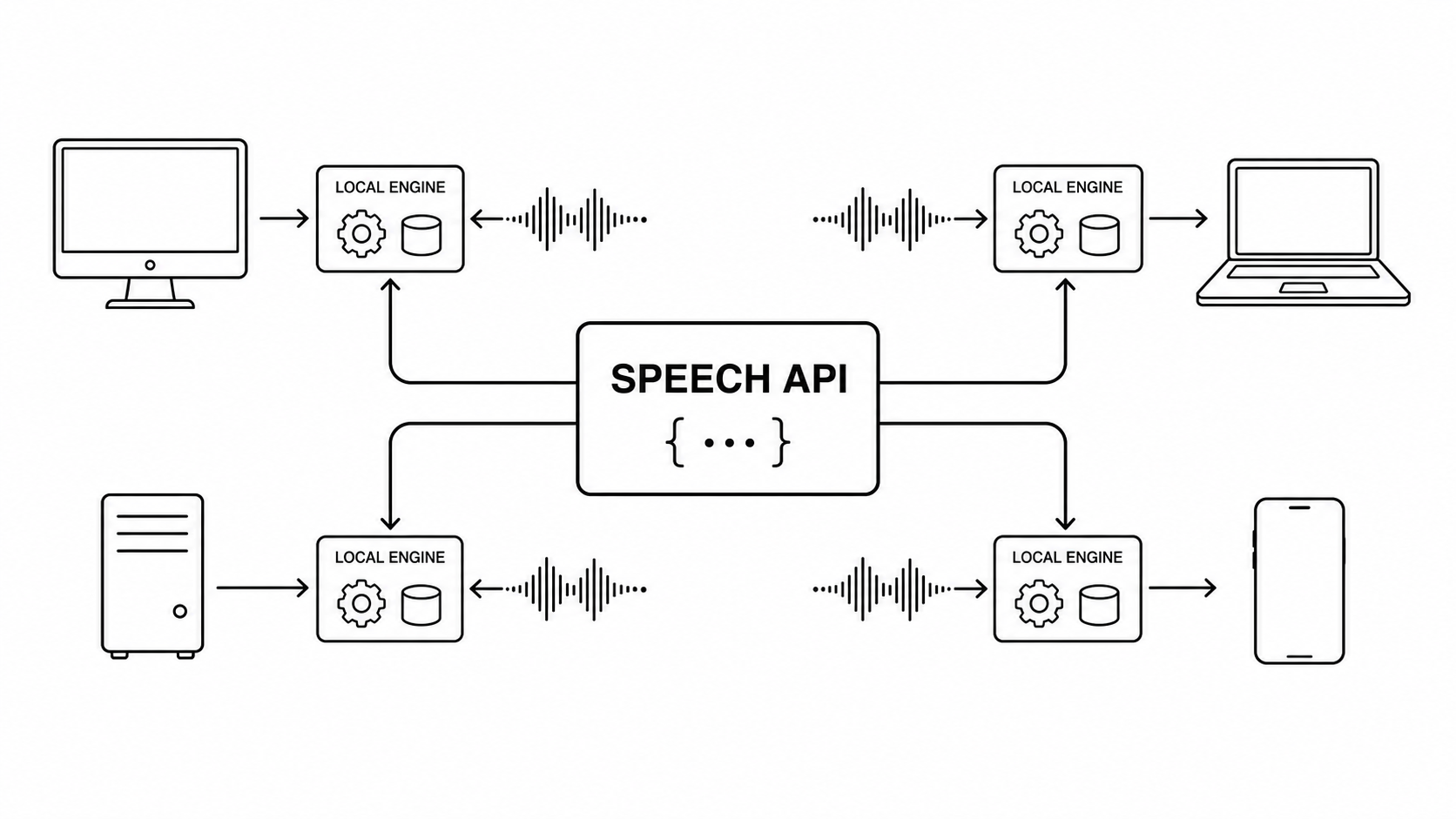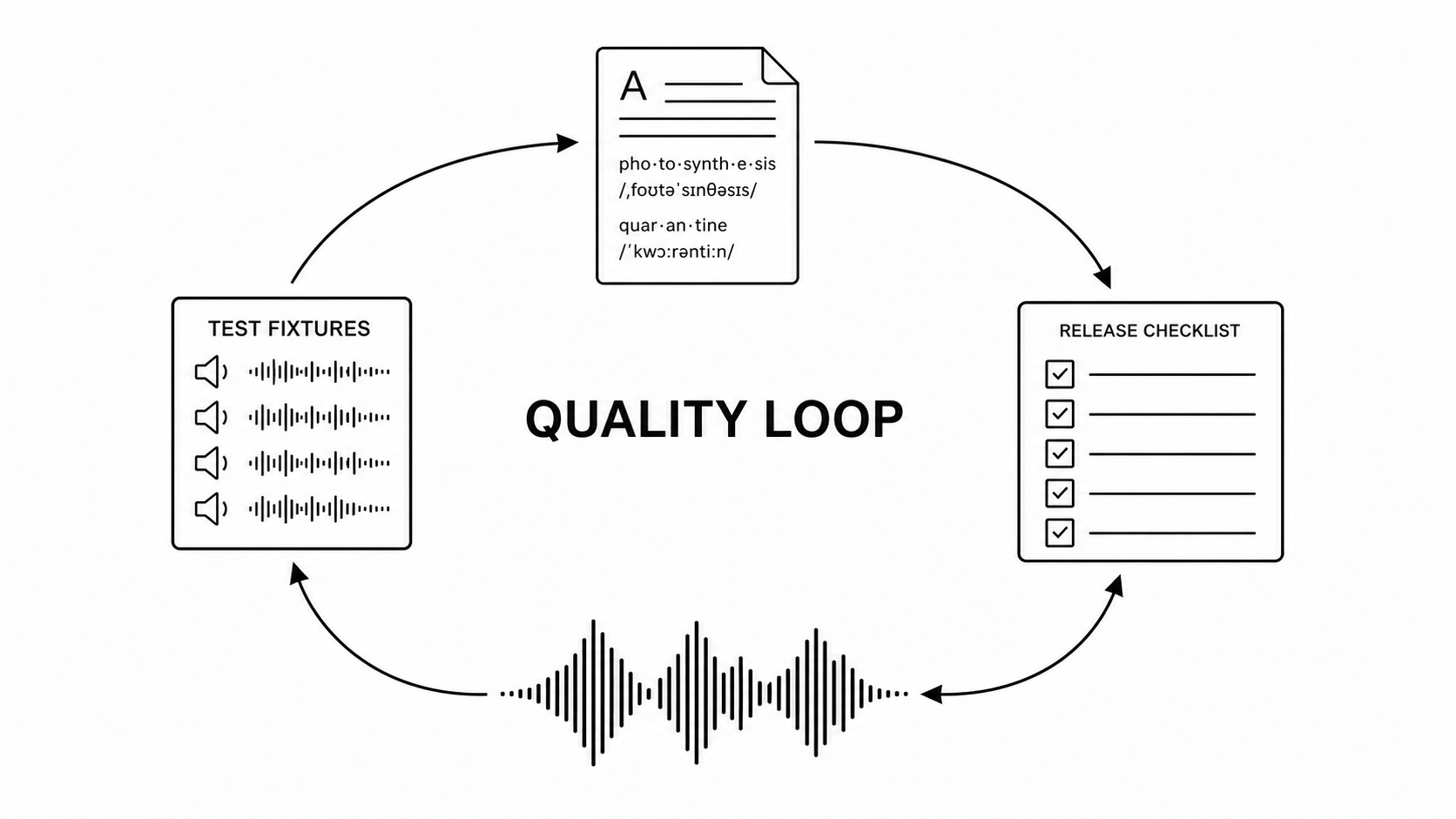
Local TTS does not become trustworthy because the model sounds nice in a demo.
Trust comes from repetition. Fixtures. Labels. Latency budgets. Release gates. The boring machinery that catches bad speech before users hear it.
The loop is simple:
- Pick a small set of representative text.
- Synthesize that text the exact same way every time.
- Listen closely to the output.
- Label the mistakes.
- Fix your text cleanup rules or switch your voice model.
- Write a test so the mistake never comes back.
That loop is how the product gets honest.

Build the Fixture Pack First
Start with sentences your app will actually say in production. Skip the Shakespeare unless you are building a poetry app.
If you’re building a devops tool, your fixtures should look like this:
The deployment finished at 18:42 UTC.
The nginx upstream returned HTTP 502 for 3.7 percent of requests.
Open /var/log/postgresql/postgresql-16-main.log.
CPU usage stayed above 90 percent for five minutes.
Dr. Wanjiku approved ticket CK-2041.
If you’re building a math tutor app, you need a totally different set:
Photosynthesis converts light energy into chemical energy.
Solve x squared plus five x plus six equals zero.
The answer is approximately 3.14159.
Read the sentence again, then tap continue.
And for a finance app, you’d test money and dates:
Your M-PESA balance changed by KES 2,450.
Invoice INV-2026-0041 is due on April 30.
The exchange rate moved from 129.80 to 130.15.
A great fixture pack covers the tricky stuff by category:
categories:
- numbers
- dates
- file_paths
- acronyms
- names
- domain_terms
- mixed_language
- long_sentences
- urgent_alerts
Keep the first pack under fifty lines. A perfect suite nobody runs is theater.
Most “Bad Voices” Are Bad Text

TTS engines are sensitive to the exact text you feed them. Take this sentence:
Dr. Njoroge read 3 logs from /srv/api-v2 at 03:05 UTC.
That one short sentence forces the engine to make at least six guesses:
- Does
Dr.mean “doctor” or “drive”? - Does
Njorogeneed a custom pronunciation rule? - Should
3be read as “three”? - How on earth do you read
/srv/api-v2out loud? - Is
03:05“three oh five” or “zero three zero five”? - Is
UTC“U T C” or “Coordinated Universal Time”?
Your text normalizer is where you make those decisions for the engine.
Even a small pronunciation dictionary changes quality:
terms:
"Dr.":
spoken: "doctor"
when: "before_person_name"
"nginx":
spoken: "engine x"
"PostgreSQL":
spoken: "post gres cue ell"
"KES":
spoken: "Kenyan shillings"
"UTC":
spoken: "U T C"
For proper names or niche industry terms, let users add pronunciation overrides. People will forgive a slightly robotic voice. They will not forgive an app that massacres their name every morning.
Normalize With Context
A basic normalizer just runs a bunch of blind string replacements. A good normalizer actually looks at the context.
Take the string 3/4. Depending on what’s around it, it could be:
- A date (March 4th).
- A fraction (three quarters).
- A chunk of a file path.
- A software version.
Similarly, the word May could be:
- A month.
- A verb (“you may proceed”).
- A person’s name.
You handle this by writing cascaded heuristics:
if token matches ISO date:
read as date
elif token appears inside file path:
read as path
elif token is all caps and short:
spell letters
elif token is in dictionary:
use dictionary
else:
leave as-is
Be careful, though: over-normalizing is a trap. Every aggressive rule you add might randomly break a completely different sentence somewhere else. Keep examples next to every rule so you know exactly why you added it.
Treat Latency Like a Budget

Do not measure only total time. Break it down:
- Normalization time
- Queue wait time
- Engine startup time
- Synthesis time
- Decoding or file write time
- Time-to-first-audio
- Playback buffer delay
- Cancellation latency
A log that says “TTS took 900 ms” is useless for debugging. Was the engine slow? Was the queue backed up? Did the OS wait for the whole file to write before it started playing? Did Windows Defender pause to scan the WAV?
Log the granular details:
{
"event": "tts.job.finished",
"voice_id": "en-us-lessac-medium",
"engine": "piper",
"chars": 142,
"normalize_ms": 3,
"queue_ms": 0,
"synthesize_ms": 488,
"audio_ms": 6120,
"first_audio_ms": 530,
"rtf": 0.079
}
Real-time factor (RTF) is the cleanest efficiency number:
rtf = synthesis_ms / audio_duration_ms
If you’re building interactive UI, care deeply about first_audio_ms. If you’re building background narration, care more about rtf and stability.
Log Defects, Not Vibes
When a sentence sounds wrong, do not write “bad voice.” Classify the failure.
Keep a simple table:
fixture_id, engine, voice, defect, severity, note
infra-004, piper, lessac, acronym, medium, "UTC read as a word"
finance-002, piper, lessac, number, high, "KES amount not expanded"
learn-008, kokoro, default, pause, low, "pause too long after comma"
Useful defect categories include:
- Pronunciation
- Number reading
- Acronym handling
- Pause or rhythm
- Clipped audio at the end
- Volume jumps
- Latency spikes
- Crashes
- Unsupported characters
- Licensing issues
Classifying the defect tells you where to fix it. A pronunciation issue means you need a dictionary update. Clipped audio means you might need silence padding. A crash means you need an engine update or smaller chunks.
Make Bad Voices Fail the Release
Before you push a voice update, make it pass a gate:
Voice release gate
[ ] model checksum changed intentionally
[ ] config checksum changed intentionally
[ ] license file present
[ ] sample fixture pack synthesized
[ ] WAV smoke tests passed
[ ] latency within budget on low-end device
[ ] pronunciation regressions reviewed
[ ] rollback path documented
Automate the basics in CI:
For each fixture:
synthesize audio
assert exit code is 0
assert WAV decodes
assert duration is greater than 250 ms
assert no sentence exceeds timeout
Then, do human spot-checks on the tricky stuff:
- Brand names
- People’s names
- Money
- Dates
- Acronyms
- Short, urgent alerts
Do not ask your QA tester, “Does it sound good?” Ask questions that catch product failures:
- Did it actually say the right words?
- Was anything embarrassing?
- Did it change the meaning of the sentence?
- Did it start fast enough?
- Did cancellation work?
- Would this be annoying if you heard it ten times a day?
That last question is the most important. A lot of voices sound amazing in a demo but drive users crazy when repeated.
Private Text Must Stay Private
People choose local TTS because the text is private: messages, medical notes, devops alerts, financial balances. The logs must honor that choice.
Good logging:
{
"chars": 118,
"voice_id": "en-us-lessac-medium",
"engine": "piper",
"synthesis_ms": 420,
"error_code": null
}
Terrible logging:
{
"text": "Your account balance is $14,000"
}
If raw text is absolutely required for debugging, make it opt-in, temporary, and easy for the user to inspect before it goes anywhere.
The Stack That Earns Trust
A trustworthy local TTS system is a stack:
- A stable product API
- One solid neural engine
- A tiny fallback engine
- Voice metadata and checksums
- A smart text normalizer
- A custom pronunciation dictionary
- Sentence-level queueing
- Audio caching
- Granular errors
- Timing telemetry
- Fixture-based QA testing
- A real release checklist
That list looks large, but the order is manageable:
- Produce one single WAV locally.
- Wrap that voice and its metadata into a bundle.
- Put a clean Speech API in front of the engine.
- Add sentence queues and cancellation.
- Add your fallback engine.
- Build out your fixture-based quality checks.
- Add release gates for voice updates.
This is how local TTS stops feeling like a fragile science project and starts feeling like reliable engineering. It works offline, respects privacy, stays testable, and survives model upgrades.
Most importantly, your app isn’t just borrowing a voice from the cloud anymore. It truly owns its voice.