The first load test made SQLite look guilty.
AuthOS, a Rust authentication platform with SQLite, PostgreSQL, and MySQL support, collapsed at roughly 130 requests per second with a 17.69 second P95 on the SQLite backend.
The lazy conclusion would have been obvious: SQLite cannot handle serious auth traffic.
The lazy conclusion was wrong.
The application was asking SQLite, Tokio, and Argon2 to do the wrong work on the wrong path. Blocking crypto sat on the async runtime. Audit logs wrote synchronously. “Last seen” updates spammed the database. Saturation turned into hoarding instead of rejection.
After moving CPU work off the runtime, buffering audit writes, debouncing noisy updates, and failing fast under pressure, the SQLite backend reached a shape that can plausibly serve 40 million daily requests on a single node.
The fix started with respecting SQLite’s actual shape.
The Starting Point Was a Death Spiral
The first version worked. That is the dangerous part.
The SSO API handled real flows: Platform Owners approving organizations, admins managing webhooks, and users logging in through OAuth. It was correct enough to demo and complete enough to trust.
Then load testing stripped away the comfort. The system collapsed at about 130 requests per second.
- Throughput: ~130 req/s (Saturated)
- Latency (P95): 17.69 seconds (Unusable)
- Diagnosis: The system was suffering from Resource Starvation.
- CPU Blocking: The heavy lifting of cryptography (specifically the Argon2 password hashing used during user registration and login) was running on the async event loop, choking the runtime.
- Write Contention: Every single API request was fighting for a lock. Whether it was the
auth_callbackhandler updating a “last seen” timestamp or the audit logger recording auser.loginevent, synchronous writes were locking the SQLite database, forcing every read operation to queue up indefinitely.
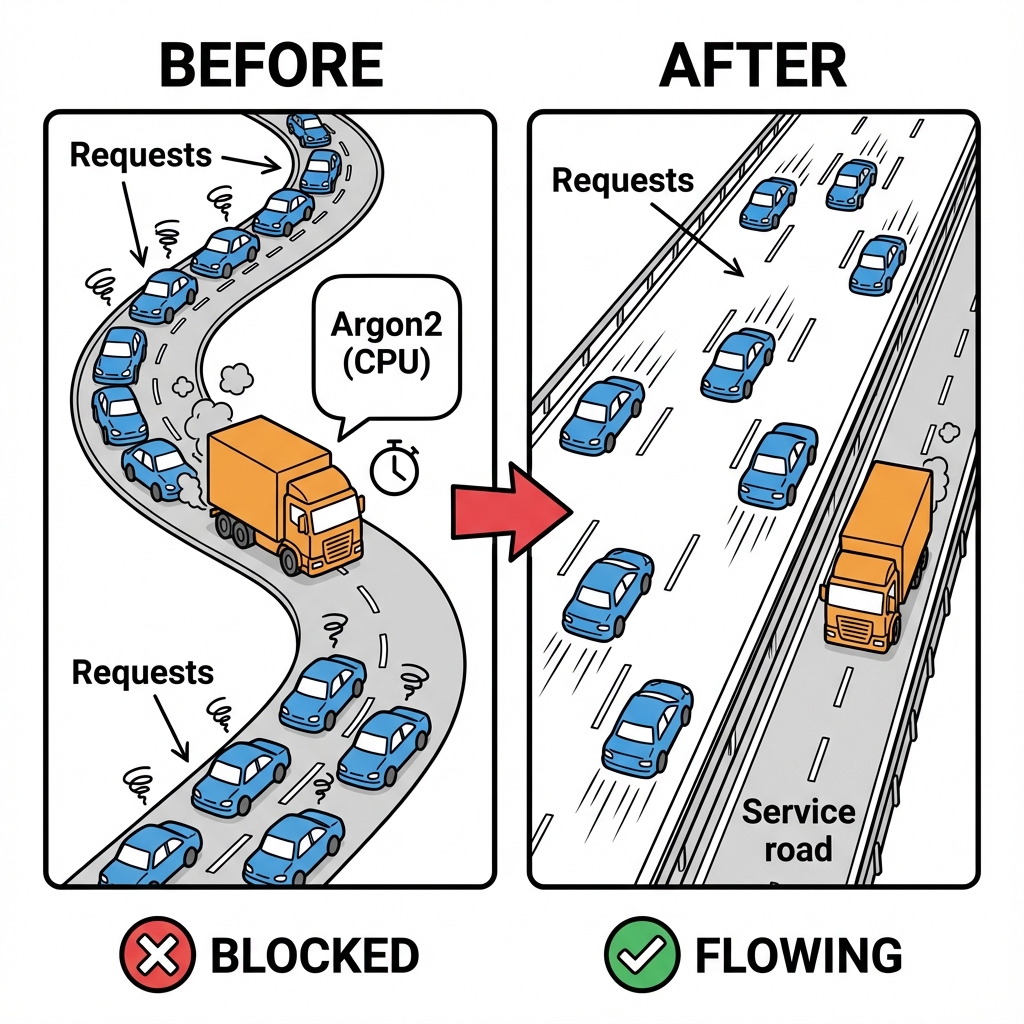 Fig 1: Evolution from a blocking, synchronous monolith to a non-blocking, event-driven architecture.
Fig 1: Evolution from a blocking, synchronous monolith to a non-blocking, event-driven architecture.
The Fix Was Discipline, Not a New Database
SQLite was not the enemy. Our request path was.
The fixes were not exotic. Move blocking CPU work away from the event loop. Stop making every request fight for a write lock. Stop writing useless activity updates. Admit saturation early.
1. Get Argon2 Off The Event Loop
- The Problem: One login could freeze the server for everyone else. Argon2 verification halted the event loop for about 50ms.
- The Solution: I moved the heavy cryptographic work to
tokio::task::spawn_blockingand guarded it with aSemaphorelimited to 2x my CPU cores. - The Result: Authentication became isolated and throttled. A login spike could no longer punish users already inside the system.
// BEFORE: Blocking the async runtime
async fn verify_password(password: &str, hash: &str) -> bool {
// ✗ Runs on the main thread, freezing the server for 50ms
argon2::verify(password, hash)
}
// AFTER: Offloaded with concurrency limits
static CPU_LIMIT: Semaphore = Semaphore::new(8); // Max 8 concurrent hashes
async fn verify_password(password: &str, hash: &str) -> Result<bool> {
// ✓ Acquire permit (wait if too busy)
let _permit = CPU_LIMIT.acquire().await?;
// ✓ Run on a background thread, unblocking the API
tokio::task::spawn_blocking(move || {
argon2::verify(password, hash)
}).await?
}
2. Move Audit Writes Out Of The Request Path
- The Problem: Strict audit trails were killing latency. Every request triggered a disk write. In SQLite, every write competes for exclusive access.
- The Solution: I implemented an Asynchronous Buffered Actor.
- The Trade-off: Audit logs can sit in RAM for about 1 second before being flushed.
- The Result: User requests return immediately. The actor batch writes and retries in the background, absorbing SQLite
BUSYerrors without making the user wait.
// BEFORE: Synchronous Writer
async fn log_event(event: Event) {
// ✗ API request hangs here until disk I/O completes
db.insert(event).await;
}
// AFTER: Asynchronous Actor
async fn log_event(event: Event) {
// ✓ Instant return! Pushes to an in-memory channel
audit_sender.send(event).await;
}
// Background Worker (The Actor)
async fn run_audit_actor(mut receiver: Receiver<Event>) {
let mut buffer = Vec::new();
while let Some(event) = receiver.recv().await {
buffer.push(event);
if buffer.len() >= 100 || timeout_elapsed() {
// ✓ Efficient batch write in background
db.insert_batch(buffer).await;
buffer.clear();
}
}
}
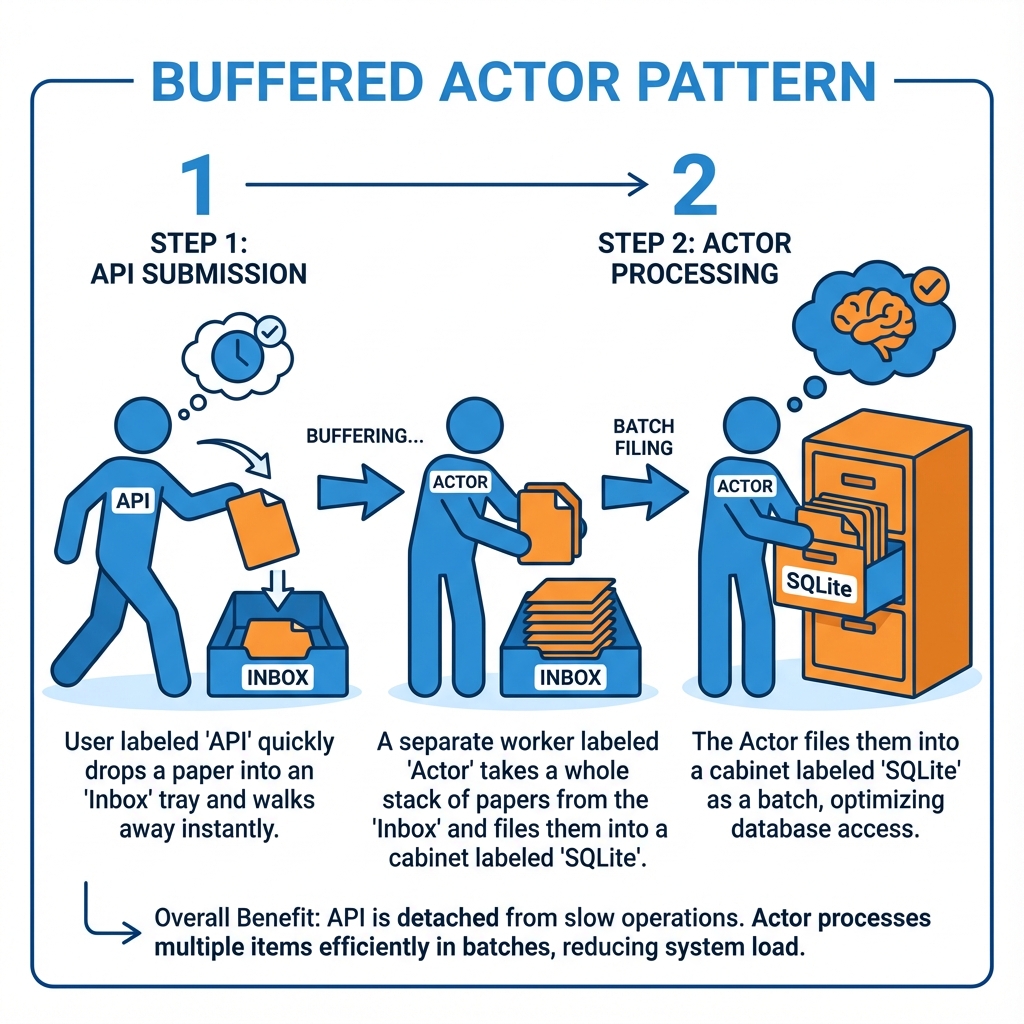 Fig 2: The Buffered Actor pattern decouples high-volume writes from the critical latency path.
Fig 2: The Buffered Actor pattern decouples high-volume writes from the critical latency path.
3. Stop Writing The Same Thing
- The Problem: “Last Seen” updates were written on every request. That flooded the Write-Ahead Log (WAL) for no useful reason.
- The Solution: I implemented Debouncing. The system only writes the timestamp if more than 5 minutes have passed.
- The Result: Write IOPS dropped by ~90%.
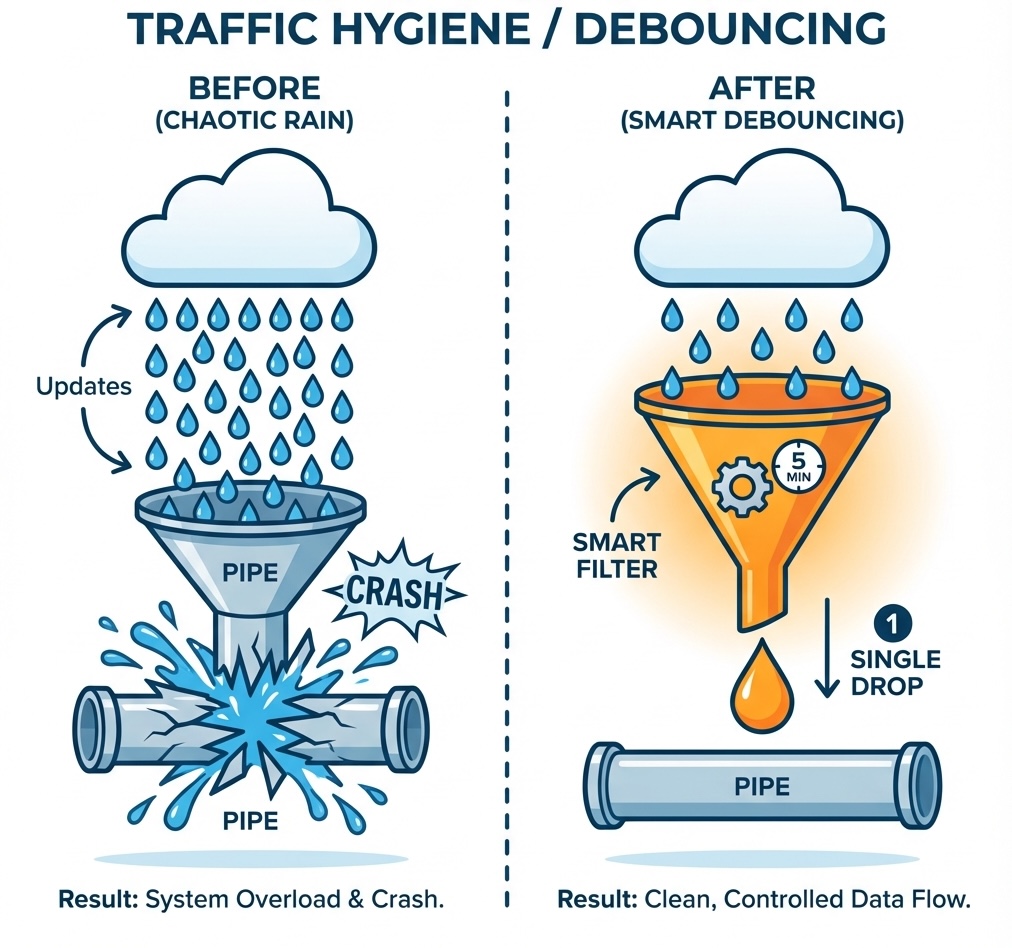 Fig 3: Smart debouncing prevents the database from drowning in identical updates.
Fig 3: Smart debouncing prevents the database from drowning in identical updates.
// BEFORE: Write on every request
async fn track_activity(user_id: Uuid) {
// ✗ Floods the WAL with identical updates
db.update_last_seen(user_id, now()).await;
}
// AFTER: Smart Debouncing
async fn track_activity(user_id: Uuid) {
let last_seen = cache.get(user_id);
// ✓ Only write if > 5 minutes have passed
if last_seen < now() - Duration::from_mins(5) {
db.update_last_seen(user_id, now()).await;
cache.set(user_id, now());
}
}
4. Fail Fast Instead Of Hoarding Work
- The Problem: At 1000 concurrent users, the queue kept growing until requests timed out after 30 seconds.
- The Solution: I implemented
TryAcquiresemantics on the Login Semaphore and set the SQLite Writer timeout to a strict 3 seconds. - The Result: The system now knows its limit. It sheds load with
429 Too Many Requestswhen saturated, so accepted requests are not buried behind work that should have been rejected.
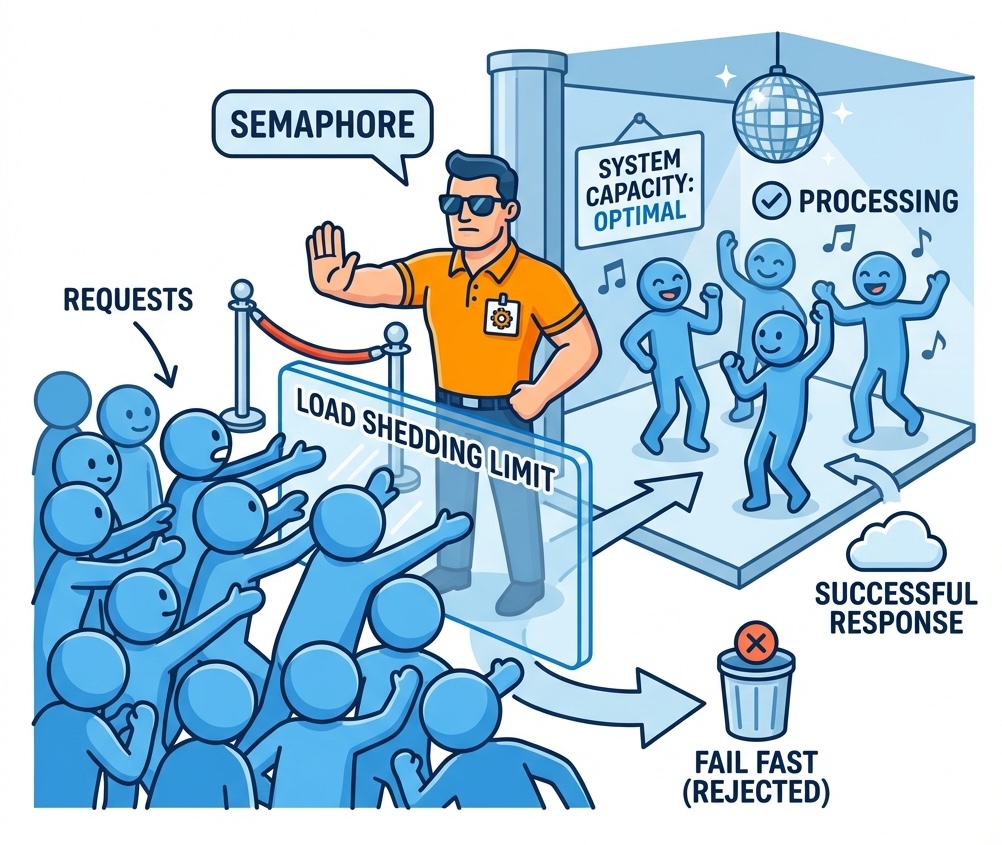 Fig 4: The semaphore rejects excess work before accepted requests drown behind it.
Fig 4: The semaphore rejects excess work before accepted requests drown behind it.
// BEFORE: Unbounded Queue
async fn login(creds: Credentials) -> Result<Token> {
// ✗ Queues forever if system is overloaded (30s timeouts)
let _permit = CPU_LIMIT.acquire().await?;
process_login(creds).await
}
// AFTER: Fail Fast Protection
async fn login(creds: Credentials) -> Result<Token> {
// ✓ Fails instantly if queue is full
let _permit = CPU_LIMIT.try_acquire().or_else(|_| {
Err(Error::TooManyRequests("System saturated, try again later"))
})?;
process_login(creds).await
}
The Final Scoreboard
The result is a useful defense of a SQLite-first architecture. Not blind faith. Measured faith.
| Metric | Initial State | Optimized State (Moderate Load) | Optimized State (Saturation) |
|---|---|---|---|
| Throughput | ~135 req/s (Unstable) | 210 req/s (Stable) | 467 req/s (Maxed) |
| P95 Latency | 17,690 ms | 4.88 ms | 2,720 ms |
| Error Rate | 0% (but unusable) | 0.00% | 0.01% |
| Bottleneck | CPU & DB Locks | None (Server Bored) | DB Connection Pool Limit |
 Fig 3: Latency dropped by 4 orders of magnitude while throughput tripled.
Fig 3: Latency dropped by 4 orders of magnitude while throughput tripled.
Key Engineering Takeaways
- SQLite can carry serious work: With WAL mode, a dedicated Writer Actor, and
IMMEDIATEtransactions, SQLite sustained 467 requests/second mixed with heavy writes. That is enough for serious software. - Async $\neq$ Non-blocking: Marking a function
asyncdoes not make CPU work disappear. Argon2 had to leave the runtime path. - ACID is a Design Choice: Critical user data stays strictly consistent. Audit logs and telemetry can be eventually consistent when the product allows it.
- The 5ms Win Matters: A 4.88ms P95 latency on a full authentication flow, including database work, application logic, and crypto, is the kind of result people usually assume requires a more expensive architecture.
Complexity Has To Earn Its Place
This system can handle about 40 million requests per day on a single node using a local file database.
That does not mean every system should use SQLite forever. It means complexity should earn its place. Postgres, Redis, and microservices are not moral upgrades. They are tools for specific pressure.
Most teams do not need to escape SQLite. They need to stop abusing it.
Appendix: The 25M MAU Estimation
The 25 Million Monthly Active Users (MAUs) estimate comes from the measured moderate-load result:
The Math:
- Benchmark Throughput: The optimized system sustains 210 requests/second at moderate load.
- Daily Capacity: 210 RPS $\times$ 86,400 seconds = ~18.1 Million requests/day.
- Requests per User: I assume an average of 4 authentication requests per Daily Active User (DAU).
- DAU Capacity: 18.1M / 4 = 4.5 Million DAUs.
- DAU/MAU Ratio: Assuming a standard engagement ratio of 20%: $$ 4.5\text{M DAU} / 0.20 = \textbf{22.5 Million MAUs} $$
I rounded this to 25M because the saturation limit was higher at 467 RPS, which suggests more headroom.
References:
- Estimating MAU from DAU: “The DAU/MAU ratio helps estimate the total active user base from daily traffic. For SaaS, a 13–20% ratio is a standard benchmark.” (Mixpanel: What is DAU/MAU? )